一文掌握 Protobuf
概述
Protocol Buffers are a language-neutral, platform-neutral extensible mechanism for serializing structured data.
Protobuf 是一种语言无关、平台无关、可扩展的 序列化 机制。
Protobuf 具有以下特点:
- 数据结构紧凑
- 解析速度快
- 跨编程语言
工作机制
Protobuf 工作机制如下图所示: 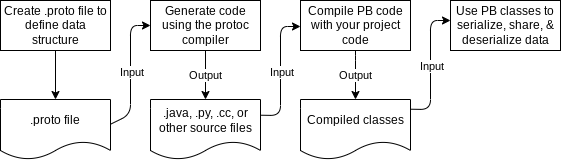 图中存在以下几个关键概念:
图中存在以下几个关键概念:
.proto数据格式定义文件:使用特定的语法定义消息的结构。- protoc 编译器:将
.proto定义编译成特定语言的源代码。 - 消息编码格式:我认为的 protobuf 的核心。
使用案例及建议
许多项目使用了 protobuf,例如:
另外,官方建议在如下场景应 避免 使用 protobuf:
- protobuf 假设消息会一次性加载到内存,因此不适合大型数据。
- 同样的数据被 protobuf 序列化后得到的字节流可能不同,因此不适合直接通过字节流比较数据是否相同的场景。
- 对于数据压缩的需求场景,由于 protobuf 的编码格式不是专门的数据压缩算法,针对图像、视频等数据,应使用更专用的算法。
- 对于涉及大型多维浮点数数组的数据科学场景,应使用更有效率的算法。
- 对于非面向对象的编程语言支持不完善。
- protobuf 消息本身不能描述消息的内容,必须结合
.proto文件解析后才可使用。 - protobuf 不是正式标准,在使用时需要考虑是否合法合规。
Proto3 语法
Protobuf 设计了一套专用语言来定义结构化数据,该定义需保存在 .proto 为后缀的文件中。
Protobuf 定义语言分为 proto2 和 proto3 两个版本,这里只介绍 proto3 版本。
Message 类型
Message 类型用于定义一个消息,下面是一个例子:
syntax = "proto3";
/* SearchRequest represents a search query, with pagination options to
* indicate which results to include in the response. */
message SearchRequest {
string query = 1;
int32 page_number = 2; // Which page number do we want?
int32 results_per_page = 3; // Number of results to return per page.
}其中:
- 第一行指定了使用
proto3版本,如果不写则默认为 proto2。 - 消息体中的字段定义格式为:
[type] [field_name] = [field_no];。 /* ... */- 行间注释;//- 行内注释。
字段编号
必须 为每个字段定义字段编号。在编码时,会使用字段编号 标识 字段,而不是字段名称。
字段编号有以下限制:
- 每个字段的字段编号必须唯一。
- 范围为
[1, 536,870,911],且[19,000, 19,999]为保留编号。 - 不能 使用之前使用过的字段编号,包括已经弃用的编号。
更改 & 删除字段
CAUTION
在更改 & 删除字段时需要格外小心,若操作不当会引起严重问题。
由于 protobuf 使用字段编号标识字段,重用字段编号会导致数据解析错误。 因此,在删除字段时需要 声明 弃用的字段编号,以防后面定义新字段时重用编号。
此外,protobuf 还可以将消息序列化成 JSON 或 文本(Text)格式的数据,因此,弃用的字段名称也需要声明。
Protobuf 提供了 reserved 关键字声明弃用的字段编号及名称。
message Foo {
reserved 2, 15, 9 to 11;
reserved "foo", "bar";
}更多注意事项参考 Updating A Message Type。
字段标签
我们可以为字段指定额外的标签(Label),例如:
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}字段标签有以下值:
optional:若未设置该值,则返回默认值,此时该字段不会被序列化。repeated:列表,列表中元素的顺序将被保留。map:键值对。- 不指定(默认情况):若该值为默认值,则不会被序列化。
字段默认值
消息被解析后,若没有值,则返回默认值。各类型的默认值如下:
- string:空字符串。
- bytes:空 bytes。
- bool:false。
- 数值型:0。
- enum:第一个 枚举值。
- Message 类型:取决于变成语言,具体参考 generated code guide。
对于带有 repeated 标签的类型,默认值为空(具体取值取决于编程语言,通常为空列表)。
类型组合使用
多个 message 类型可以 组合 使用,例如:
message SearchResponse {
repeated Result results = 1;
}
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}也可以在一个 message 类型 内部 定义其他 message 类型,例如:
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
repeated Result results = 1;
}Enums
下面的例子展示了如何定义一个枚举类型:
enum Corpus {
CORPUS_UNSPECIFIED = 0;
CORPUS_UNIVERSAL = 1;
CORPUS_WEB = 2;
CORPUS_IMAGES = 3;
CORPUS_LOCAL = 4;
CORPUS_NEWS = 5;
CORPUS_PRODUCTS = 6;
CORPUS_VIDEO = 7;
}IMPORTANT
- 枚举类型 必须 有一个编号为 0 的值,该值也是这个枚举类型的 默认 值。
- 枚举类型的第一个值的编号 必须 为 0。
Maps
可以使用 map 标签定义键值对:
map<key_type, value_type> map_field = N;下面是一个例子:
map<string, Project> projects = 3;WARNING
map 不能与 repeated 叠加使用。
未知字段
当消息格式发生变化时,旧版本的解析程序可能会无法解析新的数据。
Proto3 消息 保留 未知字段,并在解析期间和序列化输出中包含它们,这与 proto2 行为相匹配。
Any
Any 类型是 protobuf 的一个内置类型,它可以包含任意序列化后的字节流。要使用 Any,需要导入 google/protobuf/any.proto 文件。
import "google/protobuf/any.proto";
message ErrorStatus {
string message = 1;
repeated google.protobuf.Any details = 2;
}Oneof
如果消息包含多个字段,并且同时 最多 设置一个字段,则可以使用 oneof 关键字进行定义,该特性会节省内存。
message SampleMessage {
oneof test_oneof {
string name = 4;
SubMessage sub_message = 9;
}
}Oneof 具有如下特性:
在编写用户代码时,为 oneof 包裹的字段赋值会自动清除其余的值。
下面是一个 C++ 代码的例子:
c++SampleMessage message; message.set_name("name"); CHECK_EQ(message.name(), "name"); // Calling mutable_sub_message() will clear the name field and will set // sub_message to a new instance of SubMessage with none of its fields set. message.mutable_sub_message(); CHECK(message.name().empty());反序列化时若存在多个值,则 最后 一个值有效。
不能 添加
repeated标签。
从其他 .proto 文件导入定义
可以使用 import 关键字导入其他文件的消息定义:
import "myproject/other_protos.proto";可以使用 import public 传递依赖项,下面是一个经历版本迭代后抽离公共消息定义的例子:
// new.proto
// 将通用的消息定义从 old.proto 移动到这里// old.proto
// 导入通用的消息定义和其他消息定义
import public "new.proto";
import "other.proto";// client.proto
import "old.proto";
// 这里只会导入公共的消息定义,而不会导入其他的消息定义
// 因此无需做任何修改Packages
可以使用 package 关键字定义消息所在的包名:
package foo.bar;
message Open { ... }可以使用全限定类型名指定字段的类型:
message Foo {
...
foo.bar.Open open = 1;
...
}Services
当与 RPC 一起使用时,可以在 .proto 文件中定义 RPC 服务接口,protobuf 编译器将会根据语言生成对应的源代码。
service SearchService {
rpc Search(SearchRequest) returns (SearchResponse);
}Wire 格式编码
下面用一个例子简单感受一下 protobuf 简洁高效的编码方式。
message Test1 {
optional int32 a = 1;
}假设字段 a 的值为 150,上面的消息编码的结果为
08 96 01Base 128 Varints 算法
可变宽度整数(Variable-width integers, or varints)是 wire 格式编码的核心, 它可以使用 更少的位数 对整型数字进行编码。
在前面的例子中,字段 a 的值为 32 位整数 150,其二进制表示如下:
00000000 00000000 00000000 10010110可见前 24 位均为 0,实际有效位数只有最后 8 位。
而在实际生产实践中,越小的数字往往越经常使用。Base 128 Varints 算法也是基于这个现实提出的。
下面看一下编码过程:
# 32 位整数 150 的二进制表示
00000000 00000000 00000000 10010110
# 从低位开始,按每 7 位一组进行分组,并抛弃全部为 0 的组(无效数据)
0000001 0010110
# 按小端序排序(低位在前,高位在后)
0010110
0000001
# 为每组数据在头部添加标志位,1 代表后面还有数据,0 代表是最后一组
1 0010110
0 0000001
# 将各组拼接到一起
10010110 00000001 -> 96 01(十六进制)解码过程与编码过程相反:
十六进制 96 01 的二进制表示为
10010110 00000001
丢弃各组的第一位标志位
0010110 0000001
由于编码时使用的是小端序(低位在前,高位在后),解码时需要恢复原来的顺序。
0000001 0010110
将各组拼接起来
00000010010110 -> 150(十进制)通过上面的例子可知,原本 32 位整数 150 在编码过后只占 16 位,空间占用降低 50% 。
TLV 消息结构
Tag-Length-Value(TLV) 是通信协议中常用的编码格式,SSH、 TLS 等协议都使用了 TLV 格式的报文。
Protobuf 使用 TLV 编码格式,每个字段会被转换成字段号、字段类型和有效负载组成的记录。
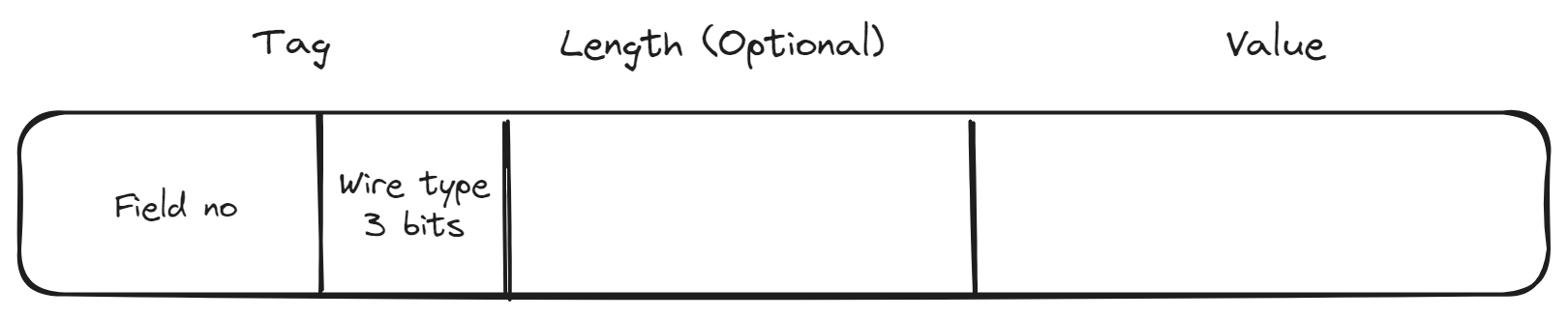
关于字段类型的取值可以参考 Message Structure。
通过查询文档可知 VARINT 类型为 0, 又因为 VARINT 通过每字节的首位确定后面的字节是否属于有效负载, 因此不需要 Length 部分。
对于前面的例子: int32 a = 1;,其 Tag 部分为
field_no type
00001 000 -> 08(十六进制)最后,将有效负载拼接到一起,就得到了本节开头中的编码结果:
Tag Value
08 96 01其他内容
前面仅介绍了针对无符号整型数据的编码,对于其他类型,protobuf 均提供了支持,这里不再一一列举。
更多内容请参考 Encoding。
代码示例
Talk is cheap, show me the code.Code is cheap, show me the GPT-4 account 😅
下面是一个在 Rust 中使用 protobuf 的例子。
NOTE
本例使用的是 prost 库, 其他支持见 Third-Party Add-ons 。
完整示例代码见 https://github.com/zou-can/rust-demos/tree/master/examples/protobuf 。
安装 proto 编译器
在 Protobuf GitHub 下载 protoc,并添加到系统路径。
设置完成后,可使用以下命令查看是否安装成功。
protoc --version
-----------------
libprotoc 27.0创建项目
cargo new protobuf --lib添加依赖
# Cargo.toml
# ...
[dependencies]
bytes = "1"
prost = "0.12"
hex = "0.4"
[build-dependencies]
prost-build = "0.12"编写 .proto 消息定义文件
// src/rpc.proto
syntax = "proto3";
package rpc.proto;
enum Corpus {
CORPUS_UNSPECIFIED = 0;
CORPUS_UNIVERSAL = 1;
CORPUS_WEB = 2;
CORPUS_IMAGES = 3;
CORPUS_LOCAL = 4;
CORPUS_NEWS = 5;
CORPUS_PRODUCTS = 6;
CORPUS_VIDEO = 7;
}
message SearchRequest {
string query = 1;
int32 page_number = 2;
int32 results_per_page = 3;
Corpus corpus = 4;
}
message SearchResponse {
message Result {
string url = 1;
string title = 2;
repeated string snippets = 3;
}
int32 code = 1;
string message = 2;
repeated Result results = 3;
}编写预编译脚本
// build.rs
use std::io::Result;
// rust 构建脚本,构建 rust crate 之前的 Hook;
// 构建脚本必须在根目录,且文件名为 build.rs;
// 构建脚本需要的依赖项可以在 Cargo.toml 的 [build-dependencies] 中声明。
fn main() -> Result<()> {
// 第一个参数指明 .proto 文件名,也可以带路径
// 第二个参数指明 .proto 文件所在的目录
// 生成的 rust 代码默认存放在 Cargo OUT_DIR 路径下,可以使用 include! 宏将其导入到我们的 rust 模块中,使用 env! 宏获取 OUT_DIR 的实际值。
prost_build::compile_protos(&["rpc.proto"], &["src/"])?;
Ok(())
}编写用户代码
// src/rpc.rs
// 使用 include! 宏导入 protoc 编译得到的 rust 代码
// "OUT_DIR" 是默认的 protobuf rust 代码输出位置。
// 注意 env! 宏获取的是编译期的环境变量,而 std::env::var() 函数获取的是运行时的环境变量
include!(concat!(env!("OUT_DIR"), "/rpc.proto.rs"));
#[cfg(test)]
mod tests {
use bytes::BytesMut;
use prost::Message;
use crate::rpc;
#[test]
fn proto_message_test() {
let req = rpc::SearchRequest {
query: String::from("query string"),
..Default::default()
};
let mut buffer = BytesMut::new();
// 序列化
req.encode(&mut buffer).unwrap();
println!("Serialized bytes for SearchRequest: {}", hex::encode(&buffer));
// 反序列化
let obj = rpc::SearchRequest::decode(&mut buffer).unwrap();
println!("Deserialized result for SearchRequest: {:?}", obj);
}
}总结
Protobuf 是一种快速高效的序列化机制,适用于对于数据传输效率要求较高的场景。 此外,protobuf 是 gRPC 的默认序列化协议,因此适合与其一起使用。
由于序列化后的消息本身不具有自解释性,需要结合消息定义文件进行解析,且修改消息结构容易出现问题, 因此个人认为不适用于需求频繁变更的场景。 另外,在跨团队、跨公司协作的场景下,会增加系统对接的复杂性,因此对于公开的服务应谨慎使用。